Table of Contents
Introduction: The Origins of Apache Hive
Initially developed by Facebook, Hive was taken up by Apache Software Foundation and it has developed Hive further as an open source under the name of Apache Hive. Hive is utilized by many companies like Amazon which uses it in the Amazon Elastic MapReduce.
What is Apache Hive?
Apache Hive is a data warehouse tool built on top of Apache Hadoop. At its core, Apache Hive serves as a powerful data warehousing tool that operates on top of Apache Hadoop. It provides a structured and organized approach to managing vast datasets, making them accessible for reporting and data analysis.
What is a Data Warehouse?
A data warehouse is a central repository of integrated data from one or more sources. The sources could be e-commerce websites, mobile phone data etc. This data warehouse is used for reporting and data analysis.
Hive: The Data Warehouse Tool
Yes and no. Hive is just a tool – a data warehouse tool. Hive is not a data warehouse. That means Hive does not have storage of its own. It is built on top of Hadoop and has the following architecture:
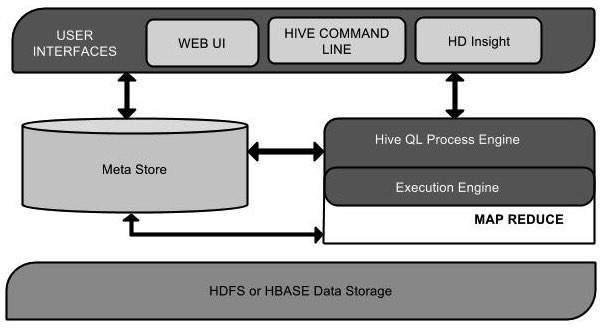
- At the bottom, you have storage applications like HDFS or HBase.
- At the middle level, you have Hive metastore as well as HiveQL Process Engine and Execution engines like MapReduce, Spark or Tez.
- The top-most level consists of user interfaces like Hive Command Line and Web UI like HUE or HD Insight.
Key Components of Hive
Apart from Metastore, execution engine and user interfaces Hive consists of another three main components:
- Driver: It acts as a controller that receives HiveQL statements. It starts execution by creating sessions and monitoring the lifecycle and the progress of execution.
- Compiler: It compiles the Hive query and converts it into an execution plan. This plan has tasks and steps that need to be performed to get the desired output. It converts the query to AST (Abstract Syntax Tree) and post completion of compatibility and compile time errors it converts AST to DAGs (Directed Acyclic Graphs).
- Optimizer: Optimizer performs various transformations in the query to get a better performance.
Hive Metastore and Execution Engines
As said earlier Hive is built on top of HDFS storage. That means Hive builds schema on top of data that is already present in HDFS. This is a key difference between RDBMS which is schema on write (schema is already present before data insertion) and Hive which is schema on read (you can create schema as per your wish on top of the data).
Hive metastore is a database like MySQL or Postgres which stores metadata of tables, databases, columns, and their datatypes and HDFS mapping.
A HiveQL process engine is a mechanism that generates or translates Hive Query to MapReduce or Spark program and executes that program to get the desired results. You can have either MapReduce Spark or Tez as the execution engines in Hive.
Structured Data and Hive
As you know Hadoop stores all types of data – structured, unstructured, and semi-structured. But Hive is specifically used to store or access structured data of Hadoop and it cannot deal with unstructured data. Unstructured data is purely handled by MapReduce or Spark. Please follow the below table for more details:

Hive vs. Traditional RDBMS
Hive is used for Online Analytical Processing (OLAP) as compared to traditional RDBMS that is used for Online Transactional Processing (OLTP). There are so many differences between Hive and traditional RDBMS. A few of them are listed below:

Conclusion: Exploring the World of Apache Hive
Apache Hive represents a pivotal player in the realm of big data, offering a structured approach to managing and analyzing data within the Hadoop ecosystem. Its unique architecture and compatibility with various execution engines make it a valuable asset for organizations seeking to make sense of their data.
Want to Learn More About Hive?
Visit the Apache Hive Official Website to get more information.
Learn about the Ultimate Guide to Google Cloud SQL.
Leave a Reply